Predicción para una mejor gestión de logística: Ciencia de Datos en una terminal portuaria mexicana
21 de Mayo de 2025

Adolfo De Unánue
Director de investigación y facultad

Elena Villalobos Nolasco
Investigadora Asociada

Zaid Hernández Solano
Estudiante de la Maestría en Ciencia de Datos y Políticas Públicas
Neiva Calvillo Zacarías
Estudiante de la Maestría en Ciencia de Datos y Políticas Públicas
La operación de contenedores dentro de una terminal portuaria implica decisiones complejas y dinámicas: ¿dónde colocar cada contenedor?, ¿cuáles saldrán antes?, ¿cuáles pasarán por servicios especiales? Responder a estas preguntas de forma anticipada puede marcar la diferencia entre una operación eficiente y una costosa.
Este blog presenta el desarrollo de un producto de datos diseñado por el Centro de Ciencia de Datos (CCD) de la Escuela de Gobierno y Transformación Pública del Tecnológico de Monterrey, en colaboración con una Terminal de Contenedores Especializada (TEC) en un puerto del país, con el objetivo de mejorar la gestión de contenedores en el patio. Para lograrlo, el sistema utiliza técnicas avanzadas de ciencia de datos, procesamiento de texto y aprendizaje automático que permiten anticipar información clave sobre cada contenedor, como su tiempo de estadía o sí requerirá servicios especiales.
Este proyecto ofrece un ejemplo concreto de cómo la ciencia de datos puede integrarse a los procesos logísticos en contextos reales, con impactos operativos, económicos y ambientales, como se describe en las siguientes secciones.
Inteligencia artificial para la mejora en la gestión de contenedores en terminales portuarias
Mover y colocar contenedores dentro de una terminal portuaria es una tarea compleja que impacta directamente en la eficiencia operativa. Uno de los principales retos en la gestión del patio de una terminal es el reacomodo de contenedores: cuando un contenedor que debe salir pronto está bloqueado por otros colocados encima, es necesario moverlos para liberar el que se encuentra “enterrado”. Este tipo de maniobras genera demoras, incrementa el uso de maquinaria y eleva los costos operativos.
En teoría, este problema podría resolverse mediante modelos de optimización. Sin embargo, para aplicarlos se requiere contar con información completa y anticipada sobre cada contenedor, como si requerirá servicios especiales o en qué momento saldrá de la terminal. En la práctica, esta información no siempre está disponible, y cuando lo está, no se tiene de manera oportuna. Además, datos clave como el tipo de mercancía o el cumplimiento de procesos aduanales suelen ser inciertos o dependen de factores externos a la terminal.
Por ello, en lugar de centrarse únicamente en optimizar con información perfecta, el proyecto adopta un enfoque predictivo: estimar de forma anticipada cuánto tiempo permanecerá cada contenedor dentro de la terminal. Esta estimación permite tomar mejores decisiones de estiba desde el inicio, reduciendo la necesidad de reacomodos posteriores. Siguiendo esta lógica, si se predice que un contenedor tendrá una estadía corta –por ejemplo, uno o dos días–, lo más eficiente es ubicarlo en una posición de fácil acceso, priorizándolo frente a aquellos con permanencias más prolongadas.
Además del tiempo de estadía, también centramos gran parte de los esfuerzos en la predicción del servicio aduanal, ya que este factor influye de manera significativa en los movimientos de desperdicio dentro del patio. La mayoría de los movimientos adicionales en la terminal están relacionados con contenedores que requieren revisión o trámite por parte de la aduana. Anticipar qué contenedores pasarán por este proceso permite planear mejor su ubicación inicial y reducir el número de maniobras necesarias, mejorando así la eficiencia operativa.
Al contribuir a una operación más sostenible y racionalizada dentro de un nodo logístico clave, se generan aprendizajes y herramientas que pueden ser transferidos a otros sectores estratégicos, como el transporte, el comercio exterior o la gestión ambiental. La mejora en la gestión de recursos en estos entornos tiene el potencial de generar impactos positivos concretos, como la reducción del desperdicio operativo, el uso más eficiente de insumos y una disminución en la huella ambiental de las actividades logísticas.
Metodología: enfoque sistemático para la predicción de servicios y tiempos de estadía de contenedores
La aproximación metodológica desarrollada en este proyecto se traduce en un producto de datos: un sistema construido a partir de la información disponible –datos– que se integra al contexto operativo específico de la terminal portuaria y se adapta a sus flujos de trabajo.
Este sistema está diseñado para apoyar a quienes toman decisiones, brindándoles información clave de forma oportuna, confiable y útil para la acción. Su propósito es servir como una herramienta práctica para planear y ejecutar intervenciones adaptadas a las necesidades reales de la operación. En este caso, su objetivo central es contribuir a resolver el problema del reacomodo de contenedores, facilitando decisiones de estiba más informadas desde el momento en que los contenedores arriban a la terminal.
El sistema se integra mediante:
Procesamiento de lenguaje natural (NLP), utilizado para extraer y estructurar información relevante a partir de textos no estructurados;
Algoritmos de búsqueda basados en grafos, que permiten vincular datos entre múltiples fuentes y mejorar la calidad de la información disponible;
Modelos de aprendizaje automático como random forest, regresión logística y árboles de decisión, para predecir comportamientos futuros de los contenedores;
Diseño de infraestructura de datos, que asegura un flujo eficiente de información, desde la recolección hasta la entrega de resultados al usuario final.
Además, se aplicaron prácticas rigurosas de validación de modelos, como la validación temporal cruzada, y la evaluación mediante métricas de desempeño adecuadas a las restricciones de la terminal para garantizar que el sistema sea robusto y confiable en escenarios reales.
El producto de datos permite anticipar, para cada contenedor que arribará en las próximas 24 horas:
El tiempo de estadía dentro de la terminal, clasificado en etiquetas discretas: menos de 2 días, 2 días, 3 días, 4 días, 5 días, 6 días, 7 días y más de 7 días.
Sí el contenedor estará sujeto a un servicio aduanero.
Información relevante sobre el contenedor.
Estas predicciones permiten a la terminal tomar decisiones de estiba más informadas desde el inicio, minimizando reacomodos posteriores y mejorando la eficiencia operativa general.
Información disponible, tratamiento de datos e ingeniería de variables
Para el desarrollo del producto de datos fue indispensable contar con acceso a la información operativa de la terminal. Este acceso se realizó mediante conexiones seguras y bajo estrictos lineamientos de confidencialidad, con el fin de proteger tanto la identidad de los consignatarios (empresas o entidades responsables del transporte de mercancías) como el contenido de los contenedores.
Las fuentes de datos proporcionadas por la terminal contienen información sobre las operaciones y movimientos de los contenedores, desde su arribo hasta su salida, así como sus características físicas y logísticas. A partir de este conjunto, seleccionamos como variables predictoras aquellas que estaban disponibles antes de que el contenedor arribe a la terminal.
Realizamos un análisis descriptivo y gráfico exploratorio para comprender mejor el comportamiento de las variables y su contexto operativo. Adicionalmente, se llevó a cabo un esfuerzo por reconstruir una línea del tiempo con las variables presentes en la base de datos, lo que permitió identificar con mayor precisión el momento en que eran registradas en el sistema. Esta reconstrucción temporal fue clave para definir qué variables podían ser utilizadas como insumos válidos para las predicciones.
Uno de los principales desafíos en el uso de los datos operativos fue el campo que describe la mercancía contenida en los contenedores. Este campo es de texto libre, es decir, no sigue un formato estandarizado ni una lista cerrada de opciones. Como resultado, las descripciones varían ampliamente entre registros, lo que dificulta su uso directo como variable para los modelos predictivos.
Para hacer útil esta información, fue necesario aplicar técnicas de procesamiento de lenguaje natural (NLP en Chowdhary, K. R. 2020b) que permitiera limpiar, estructurar y clasificar el contenido de estas descripciones. Como referencia para esta clasificación se utilizó el Sistema Armonizado de Designación y Codificación de Mercancías (HS, por sus siglas en inglés), un estándar internacional que clasifica los productos mercantiles en capítulos, partidas y subpartidas mediante un código numérico. El sistema cuenta con 21 secciones principales y 97 capítulos, que agrupan tipos de mercancía según su naturaleza o uso. Este catálogo funcionó como base para asignar una categoría formal a cada descripción textual.
Para vincular las descripciones de texto libre con las categorías del catálogo HS, se utilizó la métrica TF-IDF (Term Frequency – Inverse Document Frequency), una técnica común en recuperación de información y minería de texto que pondera la importancia de una palabra según su frecuencia en el documento y en el corpus (Manning, Raghavan & Schütze, 2008). Esta técnica permitió identificar qué palabras son más relevantes dentro de las descripciones de mercancía, y a estimar a qué capítulo del catálogo HS corresponden.
Gracias a esta estrategia, se logró generar una nueva variable —basada en la sección o el capítulo del catálogo HS— que permitió clasificar los contenedores cuya mercancía no contaba con un código especificado de forma clara. Antes del procesamiento, sólo era posible identificar el código HS en aproximadamente el 25 % de los registros, ya que su inclusión dependía de que los usuarios lo capturaran manualmente. Con el nuevo enfoque, se alcanzó una cobertura de clasificación cercana al 88 %, lo que convirtió a esta variable en uno de los insumos más valiosos para los modelos predictivos del proyecto.
Otro reto importante fue la variabilidad en los nombres de consignatarios registrados en la base de datos. Al tratarse de un campo de texto libre, el mismo consignatario podía aparecer escrito de múltiples formas —con errores tipográficos, abreviaciones o diferencias en el uso de mayúsculas y puntuación—, lo que dificulta su uso como variable.
Para abordar este problema, implementamos record linkage, que consiste en una serie de técnicas para determinar si varios registros describen una misma entidad, y se usa para unir fuentes de datos diferentes o eliminar duplicados lo que permite integrar y enriquecer la calidad de la información. El record linkage que realizamos tiene una estrategia en tres pasos. Primero, se aplicó una técnica de bloqueo simple, agrupando pares de nombres que coincidieran en la primera letra (orden alfabético), para limitar las comparaciones a casos más probables. Luego, se calcularon medidas de similitud textual usando trigramas, es decir, comparando secuencias de tres caracteres para detectar variaciones comunes.
Finalmente, se seleccionaron aquellos pares con una similitud mayor a 0.5 y se aplicó un algoritmo de grafos de búsqueda en profundidad (Depth-First Search), que permite identificar todos los nombres que están conectados entre sí a través de estas similitudes (Cormen et al., 2001).
Este enfoque permitió agrupar eficazmente las diferentes versiones de un mismo consignatario, creando un catálogo consolidado con identificadores homogéneos. La reducción en la cantidad de consignatarios únicos no solo mejoró la calidad de los datos, sino que también convirtió esta variable en un componente valioso para los modelos predictivos.
Modelado
Una vez concluida la fase de construcción de variables, se inició el proceso de modelado predictivo. Para ello, se diseñó una estructura de datos organizada en torno a dos componentes principales: por un lado, la información estática de cada contenedor —como su peso, dimensiones y tipo de mercancía— y, por otro, los eventos que ocurren a lo largo del tiempo —como su llegada, entrada, salida o movimientos dentro del patio—. Esta organización temporal fue clave para reflejar el comportamiento real de los contenedores y facilitar el análisis dinámico.
Una vez puesta la organización temporal, definimos los elementos necesarios para la predicción: las cohortes (el conjunto de contenedores sobre los cuales se desea hacer una predicción), las etiquetas (lo que se quiere predecir: tiempo de estadía o servicio aduanal) y una correcta representación del tiempo, para asegurar que los modelos solo tuvieran acceso a la información que realmente estaría disponible antes del evento de interés o momento de la predicción.
Para el proceso de modelado utilizamos más de 1,000 configuraciones diferentes que varían en técnicas, hiperparámetros y subconjuntos de variables. Este proceso se realizó con ayuda de Triage, una herramienta desarrollada por el equipo de Data Science for Social Good (DSSG) para facilitar el entrenamiento de modelos predictivos en contextos reales y con impacto social. Triage permitió automatizar la creación, evaluación y comparación de modelos de forma sistemática.
En el diseño metodológico también incorporamos consideraciones clave como la revisión y validación continua de resultados, la adaptabilidad del sistema a nuevas condiciones y la transparencia en el uso de algoritmos. Esta experiencia representa un ejemplo concreto de cómo la ciencia de datos puede integrarse con éxito a los procesos logísticos, y plantea una metodología replicable en otros contextos portuarios o sectores donde el uso de información anticipada pueda mejorar la toma de decisiones.
Para medir el desempeño de los modelos desarrollados por el CCD, se emplearon dos métricas principales:
Eficiencia: Cuando el sistema selecciona un conjunto de contenedores para salir en un día determinado (o que tengan un servicio), acierta en la predicción de aquellos que efectivamente salen ese día (o tienen un servicio).
Cobertura: Dentro del conjunto de contenedores que realmente salieron en un día determinado (o que tienen un servicio), el sistema identifica correctamente aquellos que salen ese día (o tuvieron un servicio).
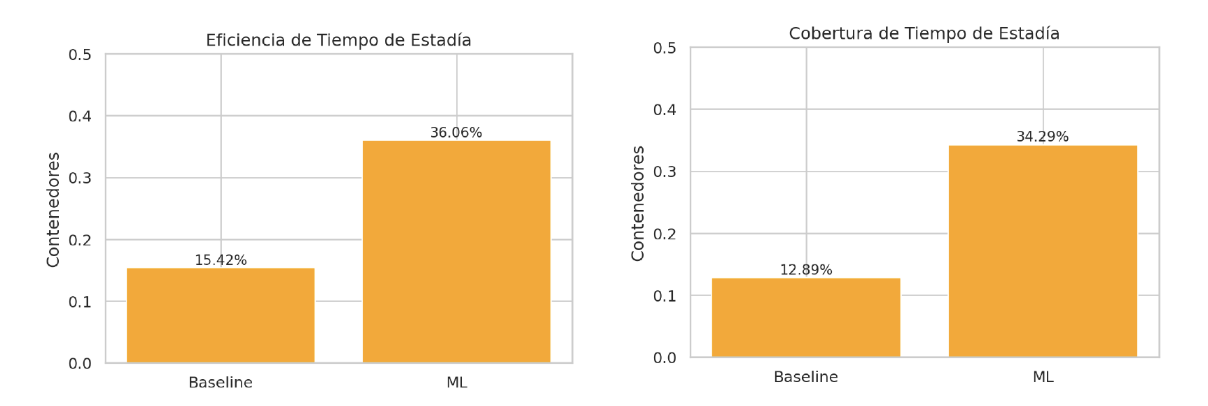
Los resultados fueron contundentes. Como se muestra en la Figura 1, en la predicción de tiempos de estadía, el modelo fue 2.3 veces más eficiente y tuvo 2.7 veces más cobertura en comparación con el baseline –lo que hace actualmente la terminal para decidir cuáles contenedores saldrán pronto–. Es decir, no solo predice mejor quién saldrá pronto, sino que encuentra más casos verdaderos entre los que efectivamente salen.
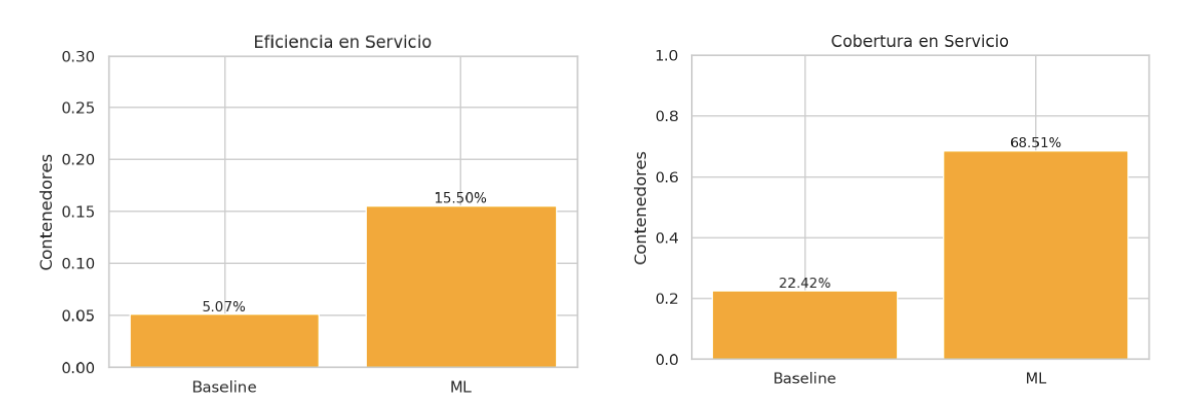
En el caso del servicio aduanal, el modelo fue aún más preciso: logró ser 3 veces más eficiente y 3 veces más amplio en cobertura que el proceso operativo existente, como se muestra en la Figura 2. Esto implica una mejora significativa en la capacidad de anticiparse a los contenedores con servicio y, por lo tanto, una herramienta clave para planear mejor la estiba desde el inicio.
Conclusiones y próximos pasos
El producto de datos desarrollado por el CCD demuestra que es posible predecir, con mejores resultados que las reglas heurísticas actuales, tanto los contenedores que requerirán servicio aduanero como los tiempos de estadía dentro de la terminal portuaria. Estos avances representan un paso significativo en la integración de herramientas de ciencia de datos en los procesos logísticos portuarios, al convertir la incertidumbre operativa en conocimiento anticipado.
Los modelos desarrollados ofrecen una nueva perspectiva para la gestión de contenedores, al permitir anticipar comportamientos logísticos con niveles de precisión que llegan hasta casi un 70%, según el intervalo temporal considerado. Esta capacidad predictiva abre la puerta a una operación más eficiente, con un uso más racional de recursos humanos y materiales, y con efectos positivos tanto en lo económico como en la reducción del impacto ambiental.
No obstante, el trabajo aún está en proceso de conclusión. Aunque el sistema predictivo ha sido desarrollado y validado técnicamente, su integración formal en los procesos operativos de la terminal aún se encuentra en etapa de prueba y ajuste. El diseño del producto de datos ya contempla su uso dentro del entorno real de toma de decisiones, pero su efectividad final dependerá de cómo se articule con la operación cotidiana. Además, como ocurre con cualquier sistema basado en machine learning, su utilidad a largo plazo requiere de un proceso continuo de reentrenamiento, que permita mantener su precisión y adaptarse a los cambios en los patrones logísticos, normativos o comerciales. En ese sentido, más que un resultado cerrado, este proyecto representa una plataforma en evolución que crecerá junto con las necesidades del entorno portuario.
Este proyecto también establece un precedente valioso para las colaboraciones entre el Centro de Ciencia de Datos y la Escuela de Gobierno y Transformación Pública con instituciones del sector privado. La experiencia adquirida, la metodología desarrollada y los aprendizajes generados pueden escalar a otros puertos, adaptarse a distintos contextos logísticos e incluso transferirse a otras industrias. En un entorno cada vez más interconectado, este tipo de soluciones ofrece una oportunidad concreta para transformar las cadenas de suministro, con impacto local y proyección global.
NOTA: Este blog describe un proyecto desarrollado por el Centro de Ciencia de Datos (CCD) de la Escuela de Gobierno y Transformación Pública del Tecnológico de Monterrey (EGobiernoyTP), enfocado en la mejora de la gestión de contenedores en una terminal portuaria mediante herramientas de ciencia de datos. El equipo está conformado por: Elena Villalobos Nolasco, profesora-investigadora, científica de datos senior en el CCD e investigadora principal; Adolfo Javier de Unánue Tiscareño, director del CCD; David Salomón Aké Uitz, gerente de proyectos; Zaid Hernández Solano, Carlos Eduardo Olvera Azuara y Roberto Villarreal Ramírez, estudiantes y miembros activos del centro.
U.S. Department of Commerce. (n.d.). Harmonized system (HS) codes. Trade.gov. https://www.trade.gov/harmonized-system-hs-codes
Data Science for Social Good. (n.d.). Triage documentation. https://dssg.github.io/triage/
Cormen, T. H., Leiserson, C. E., Rivest, R. L., & Stein, C. (2001). Introduction to Algorithms (2ª ed.). MIT Press.
Manning, C. D., Raghavan, P., & Schütze, H. (2008). Introduction to Information Retrieval. Cambridge University Press. https://nlp.stanford.edu/IR-book/
Chowdhary, K. R. (2020b). Natural Language Processing. En Fundamentals of Artificial Intelligence (pp. 603-649). Springer India. https://doi.org/10.1007/978-81-322-3972-7_19