Desmitificando los riesgos de la inteligencia artificial: explorando regulaciones globales y desafíos actuales
10 de Abril de 2024
¿Qué significa que un algoritmo o un modelo de inteligencia artificial sea peligroso? ¿Es la peligrosidad una característica inherente a la tecnología avanzada o, más bien, es una consecuencia de una aplicación inadecuada o maliciosa de ella? Los campos relacionados a la inteligencia artificial (IA) son inmensamente amplios y complejos y, por ello, su aprovechamiento no se puede simplificar en categorías binarias como "peligrosas" o "seguras". Alrededor del mundo, existe una necesidad de establecer niveles diferenciados de análisis y, en ese sentido, de considerar seriamente la implementación de regulaciones adecuadas.
La analogía de los cuchillos es útil para ilustrar este punto. En la vida cotidiana, los cuchillos son instrumentos ubicuos, potencialmente peligrosos si se usan con malas intenciones o negligencia, pero cuya utilidad y bajo un riesgo inherente generalmente no es necesario un control riguroso. En contraste, los cuchillos de chef, que requieren cierta habilidad para su uso seguro y efectivo, tienen una disponibilidad más controlada. Esto nos lleva a las bayonetas, que están sujetas a regulaciones mucho más estrictas debido a su diseño explícito para el combate. Ya no digamos cierto instrumental quirúrgico. Este espectro de regulación se refleja en la necesidad de no pensar en los algoritmos de IA como un ente único, posible de evaluar a partir de un rasero dicotómico, sino como un conjunto diverso de herramientas que requieren un enfoque matizado expresado en un variado abanico de criterios de regulación claros y objetivos.
Fantasías y realidades en los riesgos de la IA
Cuando se habla de los peligros de la IA, la imagen que suele aparecer en el imaginario colectivo es la de un sistema con conciencia, capaz de tomar decisiones de manera autónoma sin considerar, o incluso activamente ignorando, las necesidades e instrucciones humanas.
Sin embargo, este escenario por el momento es poco probable. Para reconocer cuáles son los riesgos y potencialidades del uso de la IA actuales y a corto plazo, comencemos por entender qué es la IA actual y qué tipos de usos se le ha dado. Cada vez hay más decisiones basadas en aprendizaje automático que están teniendo efectos importantes en la vida de las personas, los algoritmos más cercanos a “una inteligencia artificial” pertenecen a dicha área.
El aprendizaje automático es un área de la computación donde se crean herramientas que reciben como entrada algunos datos (por ejemplo, características demográficas de alguna persona), y devuelve alguna predicción; una categoría deseada (continuando con el ejemplo, la probabilidad de que pague a tiempo una deuda o cierto perfil de compra).
Esas herramientas son algoritmos o modelos genéricos, que se especializan en resolver cierta tarea repitiendo las tendencias de ejemplos de predicciones o categorías conocidas.
Varias aplicaciones en las que se ha comenzado a usar aprendizaje automático tienen consecuencias importantes a nivel individual y social. Por ejemplo, despidos masivos, el filtrado de currículos para la admisión a trabajos o a escuelas, asignación de recursos estatales y aprobación de préstamos por parte de entidades financieras. Incluso se han estado utilizando ese tipo de algoritmos para el apoyo de decisiones judiciales, por ejemplo, en puntuaciones para asistir la aprobación de libertad condicional.
También existen otros tipos de aplicaciones con influencia a nivel cultural, como motores de búsqueda y redes sociales que median buena parte de nuestras interacciones con el mundo, o recomendaciones de noticias que influyen en la percepción de la realidad.
El riesgo de algoritmos diseñados para influir en el comportamiento humano, especialmente en contextos políticos o sociales, es ya una realidad.
Recordemos, por ejemplo, la brecha de datos privados de más de 50 millones de usuarios de Facebook, que fueron entregados a una firma de marketing político contratada para la campaña presidencial de Donald Trump, revelada en marzo del 2018. O la colaboración de IBM con el Departamento de Policía de Nueva York para el reconocimiento facial y la clasificación racial de grabaciones de vigilancia, conocida en septiembre del mismo año.
Por último, está el ejemplo de modelos generativos de contenido como texto o imágenes. Estos son otros modelos de aprendizaje automático que están modificando la forma de ejercer distintas profesiones como la traducción de textos y diversas tareas administrativas.
Los ejemplos anteriores nos muestran que más allá de una discusión sobre la posibilidad de que la inteligencia artificial alcance autonomía o consciencia, en la actualidad ya hay usos que están moldeando nuestra cotidianeidad, a veces para bien y a veces para mal. Para mitigar los riesgos, sin dejar de aprovechar los beneficios del uso de la IA, han surgido áreas tanto de la computación como del derecho. Enseguida revisaremos algunos de los esfuerzos que se han desarrollado en las dos áreas.
Modelos robustos y la lucha contra la discriminación: avances desde la computación para un uso ético de la IA
Ningún humano que conozca los señalamientos de tráfico tendría problema en identificar qué representa la siguiente señal, inclusive si no domina el idioma inglés:

Sin embargo, Eykholt [2018] y su equipo demostraron que algo tan simple como la cinta adhesiva aplicada estratégicamente sobre una señal de tránsito - trabajo que se puede apreciar en la Figura 1 - podía engañar a un modelo de reconocimiento de este tipo de señalamientos, previamente entrenado y con un desempeño bueno, haciéndole interpretar erróneamente una señal de stop (pare) como un límite de velocidad de 45 millas por hora.
Esta clase de engaños podría conducir a ataques, por malicia o por descuido, contra el software de vehículos autónomos, con consecuencias potencialmente desastrosas para la seguridad pública, vial y, por supuesto, para vidas humanas.
Pensando en un ataque planeado, este tipo de vulnerabilidad de los algoritmos representa una amenaza que trasciende los límites convencionales de la ciberseguridad, una manipulación así no requiere acceso directo o hackeo a ninguno de los sistemas de los vehículos autónomos. Esto desafía nuestra concepción tradicional de seguridad en el ámbito de digital.
Por otro lado, existen muchos algoritmos que fallan no por planeación maliciosa, si no por no presentarles ejemplos de escenarios diversos, ¿quién no ha visto estampas de diseños pegadas en todos los postes de cualquier ciudad? Recordemos que los algoritmos extraen tendencias de ejemplos “resueltos” de la tarea que están replicando, si al modelo anterior se le hubieran mostrado ejemplos de señales con estampas y no sólo señales pulcras y bien alineadas, podría haber tenido un desempeño mejor en contextos reales.
Para contrarrestar ese tipo de fallos, desde el área de la computación se han desarrollado el concepto de “modelos robustos” y diversos métodos para alcanzarlos. Un método de estos, y retomando el ejemplo de reconocimiento de imágenes, es la “aumentación de datos”; se parte de un conjunto de ejemplos relativamente pequeño y estándar y se aumenta el número de ejemplos alterando las imágenes: rayándolas, girándolas, borrando ciertas partes. Se diría que un modelo que logra reconocer las señales en esas imágenes, aunque estén alteradas, sería más robusto que uno que no.
Existen otros esfuerzos desde el área computacional que buscan mitigar los riesgos de la IA, específicamente los de discriminación basada en atributos sensibles, como lo son el género o la etnia.
Consideremos el caso del proyecto “Boston Street Bumps” (City of Boston. [2019]), con el que se buscaba detectar baches en calles para asignación de recursos en zonas de la ciudad. Para ello lanzaron una aplicación de teléfono móvil que detectaba cuando un vehículo pasaba por un bache. Naturalmente, como en el resto de las aplicaciones, la mayoría de los usuarios eran relativamente jóvenes y de un estrato socioeconómico mayor a la media. Así, los recursos eran asignados en su mayoría a zonas donde ese grupo se concentraba.
Para detectar ese tipo de malos diseños, se han desarrollado métricas que miden el desempeño de los modelos, pero por grupo demográfico. Además, se han desarrollado modelos que no solo pretenden hacer su tarea con la mayor efectividad, sino que cumplen simultáneamente otros objetivos sociales como que el modelo no se equivoque más en un grupo demográfico que en otro.
La robustez y las modificaciones de algoritmos estándar para una IA menos sesgada son solo algunos puntos que se han atendido en la búsqueda de un uso práctico y beneficioso de la IA desde las ciencias de la computación y la estadística. Otros aspectos sumamente relevantes abarcan desde la revisión del diseño del sistema de IA, la inclusión de los grupos afectados en este, el mapeo del origen, creación y limitaciones de los datos, entre otros.
Regulación de la IA: el caso de la Unión Europea
Se han propuesto diversas regulaciones y recomendaciones, en varias partes del mundo, para mitigar los riesgos y darles certeza jurídica a las innovaciones y potenciales aplicaciones benéfica o neutrales de la IA. La Unión Europea (UE) ha tomado la delantera, al tratarse del primer esfuerzo multinacional, con el diseño formulación y aprobación de su Acta de Inteligencia Artificial (EU AI Act). Este documento normativo, resultado de un enorme esfuerzo de varios meses, se espera que entre en vigor en un plazo de 6 a 36 meses, es un paso de enorme relevancia hacia la regulación de herramientas inteligentes con el potencial de ser utilizadas de manera riesgosa.
En efecto, el EU AI Act, además de trazar como objetivos de esta regulación mantener un mercado económico único derivado de esta tecnología, así como la innovación en torno a ella, establece que es crucial clasificar como de alto riesgo a aquellos sistemas de IA independientes que, por su propósito intencionado, representan un peligro significativo para la salud, la seguridad o los derechos fundamentales de las personas. Es decir, la UE ha adoptado un enfoque pragmático que clasifica los algoritmos de IA según su riesgo potencial. Esta clasificación se ha estructurado en varias categorías, desde "riesgo inaceptable" hasta "riesgo bajo", con ejemplos específicos asignados a cada una para ilustrar los tipos de tecnologías y aplicaciones que se encuentran bajo cada paraguas de riesgo [Sioli, 2021]
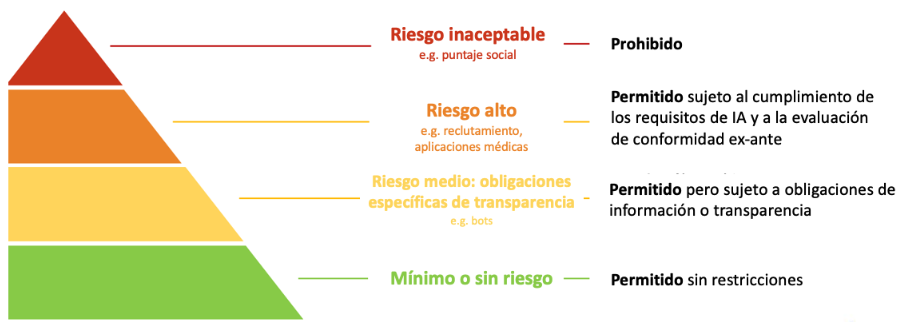
Los ejemplos más representativos de cada una de las categorías son los siguientes:
Riesgo inaceptable: puntuación social, reconocimiento facial en espacios públicos, manipulación de comportamiento
Riesgo alto: dispositivos médicos, transporte autónomo, educación, derecho
Riesgo medio: chatbots, deepfakes, reconocimiento emocional
Riesgo bajo: filtros de spam, videojuegos
Dicha clasificación no solamente proporciona un marco para la regulación, también nos permite vislumbrar cómo, y en qué medida, la IA puede afectar distintos aspectos de las esferas sociales de las personas.
Por ser una regulación internacional, diseñada para muchos países, de manera inevitable diversos aspectos y definiciones no están del todo definidos, con miras a que cada país miembro de la UE aterrice localmente rubros tan relevantes como la responsabilidad penal, civil y administrativa, además de que aún falta establecer cómo se conectará esta regulación con otras como la relativa al Internet de las Cosas.
Lo cierto es que, hasta ahora, es el proyecto regulatorio más ambicioso para mantener el difícil equilibrio entre regular y mitigar los riesgos del mal uso de esta tecnología y, a su vez, exprimir su enorme potencial beneficioso para la sociedad. Falta ver cómo se desempeñará en la etapa más complicada, esto es, su implementación y operación con el resto de las normas jurídicas. Y algo no menos importante, que ya ha sucedido con otras legislaciones europeas, como en el caso de su regulación de datos (GDPR, por sus siglas en inglés), cómo esta nueva regulación impactará en la práctica más allá de las fronteras de la UE.
Otro pendiente es verificar su capacidad de mantenerse funcional ante una tecnología que avanza a una velocidad inédita; justo ya diseñada, cuando esta regulación estaba en pleno proceso de aprobación, fue cuando emergió con fuerza alrededor del mundo la inteligencia artificial generativa con ChatGPT.
Pero no sólo la UE está impulsando modelos regulatorios, Asia lleva años impulsando regulaciones que, si bien en no pocas ocasiones se descalifica el caso de China por su falta de credenciales democráticas, también es importante reconocer que varias de sus regulaciones tienen como origen preocupaciones como la soberanía de sus datos, la protección de su juventud frente los algoritmos de las redes sociales, ciberseguridad, entre otros.
Por otro lado, Estados Unidos, a pesar de su tradición reacia a la regulación, recientemente se sumó a este debate mediante una orden ejecutiva de su presidente Joe Biden, en la que abordan varios aspectos normativos, pero también suman un enfoque de estándares técnicos para trazar aspectos medulares de los sistemas y modelos de la inteligencia artificial.
Sobre la posibilidad de una regulación mundial, existen distintos enfoques económicos, políticos e incluso filosóficos que forman la base cultural de cada país. Mientras que algunas perspectivas priorizan al individuo, otras priorizan el beneficio grupal; asimismo hay unas que priorizan los derechos humanos y otras al consumidor. Por ejemplo, la EU AI Act prohíbe explícitamente prácticas como la puntuación social, que en países como China forman parte de la vida diaria. Esta profunda diferencia en valores refleja la complejidad de una regulación mundial de la IA, sin embargo, la naturaleza trasfronteriza del mundo digital requiere esfuerzos conjuntos.
Iniciativa desde la EGobiernoyTP
Dado que la legislación de inteligencia artificial en México todavía es un campo emergente, en la EGobiernoyTP se está llevando a cabo el proyecto de “Hacia una política regulatoria de la Inteligencia Artificial en México”. Éste consiste en cuatro series de paneles con expertos nacionales e internacionales en áreas jurídicas y computacionales. Los paneles están dedicados a regulación de datos, de modelos de inteligencia artificial, de plataformas digitales y la contextualización de dichas regulaciones en México, respectivamente.
Asimismo, se publicará un texto en español que recoja dicho diálogo interdisciplinario, motivado por una selección de preguntas clave para entender el panorama actual de las regulaciones alrededor del mundo y una introducción a otros textos que las abordan de diversas maneras.
City of Boston. (2019). Street Bump. Recuperado de https://www.boston.gov/transportation/street-bump
European Commission. (2023). The Artificial Intelligence Act. Recuperado de https://artificialintelligenceact.eu/the-act/
Eykholt, K., Evtimov, I., Fernandes, E., Li, B., Rahmati, A., Xiao, C., Prakash, A., Kohno, T., & Song, D. (2018). Robust Physical-World Attacks on Deep Learning Models. arXiv:1707.08945 [cs.CR]. Recuperado de https://arxiv.org/abs/1707.08945
Mitchell, S., Potash, E., Barocas, S., D'Amour, A., & Lum, K. (2021). Algorithmic fairness: Choices, assumptions, and definitions. Annual Review of Statistics and Its Application, 8, 141-163
“Robust Physical-World Attacks on Deep Learning Models,”, K. Eykholt, et al., 2018. Disponible en https://arxiv.org/abs/1707.08945
Sioli, L. (2021). A European Strategy for Artificial Intelligence. En CEPS Webinar - European Approach to the Regulation of Artificial Intelligence. European Commission, DG CNECT
The Invention of “Ethical AI”. How Big Tech Manipulates Academia to Avoid Regulation: https://theintercept.com/2019/12/20/mit-ethical-ai-artificial-intelligence/