Priorización de carpetas de investigación con aprendizaje automático: una herramienta para fortalecer a las fiscalías
14 de Octubre de 2025

Fernanda Sobrino
Profesora-investigadora

Edgar Hernández
El sistema de justicia criminal en México enfrenta un rezago procesal persistente: aumentan los casos, los recursos de las fiscalías son limitados y el volumen de carpetas sin resolver crece. Entre 2018 y 2022, el número de expedientes abiertos a nivel nacional aumentó casi 60%, con más de 2.9 millones de investigaciones activas (México Evalúa, 2023; INEGI, 2023).
En este contexto, en el Centro de Ciencia de Datos e Inteligencia Artificial de la Escuela de Gobierno y Transformación Pública, colaboramos con la Fiscalía General de Justicia del Estado de Zacatecas (FGJEZ) para diseñar y evaluar un sistema de aprendizaje automático (ML) que facilite la priorización semanal de carpetas. El objetivo no es automatizar decisiones ni reestructurar flujos de trabajo: es apoyar a las y los fiscales con una lista ordenada de casos que, según patrones históricos de progresión, tienen mayor probabilidad de resolverse en el corto plazo.
El modelo opera en el Módulo de Atención Temprana (MAT), la unidad de entrada donde se reciben denuncias y se toman decisiones iniciales. Cada semana, el sistema genera un ranking sobre todas las carpetas abiertas en MAT obedeciendo la probabilidad estimada de “finalizar” en los próximos seis meses. A partir de este ranking se extrae una lista de las primeras 300 para revisión prioritaria. En este contexto, “finalizar” significa que la carpeta sale de la jurisdicción de MAT—por cierre administrativo, mecanismo alternativo o remisión a una unidad especializada.
El sistema se entrena con datos administrativos de la Plataforma de Integración de Expedientes (PIE) y se evalúa bajo condiciones que simulan el funcionamiento actual de la fiscalía. En pruebas históricas (2014–2024, con énfasis en 2023–2024), los ensambles—en particular Random Forest—obtienen un Precision@300 promedio ≈ 0.73; es decir, en promedio, 73% de los casos del Top-300 efectivamente concluyen dentro del horizonte de seis meses. La intervención no altera la operación: no reasigna casos ni impone decisiones; funciona como insumo de priorización para la revisión interna.
¿Qué datos se utilizan y cómo se preparan?
La Plataforma de Integración de Expedientes (PIE) es el sistema principal de gestión de casos de la FGJEZ desde 2014. Registra metadatos de cada investigación (delito principal, fechas clave y ubicación) y, sobre todo, una secuencia de eventos procedimentales con sellos de tiempo (por ejemplo, inicio, actualizaciones de investigación, transferencias entre unidades o jurisdicciones, solicitudes y órdenes judiciales, remisiones a tribunal y resultados). Estas trazas permiten reconstruir la trayectoria de cada carpeta en el tiempo (Sobrino et al., 2025).
La unidad de predicción son las carpetas abiertas en MAT al momento de cada corte semanal. En cada semana histórica se toma una “foto” del universo abierto y a partir de ello, se proyecta si esas carpetas saldrán de MAT en los seis meses siguientes. Aunque la predicción se focaliza en MAT, el aprendizaje se alimenta de la historia completa en PIE, incluyendo carpetas que transitaron por otras unidades.
Para garantizar coherencia, se estandarizan catálogos (delitos, unidades), se validan secuencias temporales (que los eventos sigan un orden lógico), se deduplican registros y se construyen identificadores persistentes. Dado que pueden existir cargas por lotes que concentren varios eventos en pocos días, se mitiga su efecto mediante agregados por ventanas temporales.
¿Qué características se utilizaron?
Para que los modelos aprendan de los datos históricos se construyeron distintas variables utilizando la información del PIE. Se organizan en cinco bloques:
Características de la carpeta. Fecha de apertura; delito principal; origen (denuncia ciudadana vs. parte policial); y marcadores básicos de complejidad administrativa.
Hitos y estados de investigación. Indicadores acumulados y recientes de actuaciones relevantes (p. ej., judicialización, medidas cautelares, órdenes de aprehensión, vinculaciones, mecanismos alternativos).
Dinámica de eventos. Conteos y tasas promedio en ventanas de 3, 6, 12 y 24 meses; días desde el último evento; antigüedad (días desde la apertura); y duración total del expediente.
Carga y productividad de personas y unidades. Volumen abierto y cerrado reciente por abogadas/os y por unidad; proporciones de cierre; rangos relativos para ubicar a cada unidad en su contexto operativo inmediato.
Agregados por tipo penal. Tasas históricas y recientes de cierre y volúmenes por categoría, útiles para reconocer patrones asociados a la naturaleza del delito.
Cada característica se relaciona con acciones o estados conocidos por el personal, lo que permite devolver “motivos” claros en la lista prioritaria (p. ej., “4 avances de investigación en 90 días; 2 transferencias en 6 meses; 45 días desde el último evento”).
Formulación
Planteamos el problema como una clasificación binaria: para cada carpeta abierta en MAT en la semana t estimamos si finalizará en los seis meses siguientes. Para ello comparamos modelos supervisados de distinta complejidad—Regresión Logística, Árboles de Decisión, Random Forest y Extra Trees—explorando combinaciones de hiperparámetros y ventanas temporales hasta completar 864 variantes históricas.
La evaluación sigue un esquema temporal rodante que entrena cada modelo exclusivamente con la información disponible antes de la semana evaluada, evitando así la fuga de futuro y aproximando el desempeño en despliegue real. Como puntos de referencia incluimos dos líneas base: una selección aleatoria de 300 carpetas y un ranking por tasa base construido con probabilidades históricas de cierre para casos “similares”. Finalmente, usamos Precision@300 y Recall@300 como métricas operativas, pues están alineadas con la práctica semanal de revisar 300 carpetas: la primera mide cuántas de las sugeridas sí salen de MAT en el horizonte de seis meses, y la segunda qué fracción de todas las que efectivamente salen quedó cubierta por esa lista.
Resultados
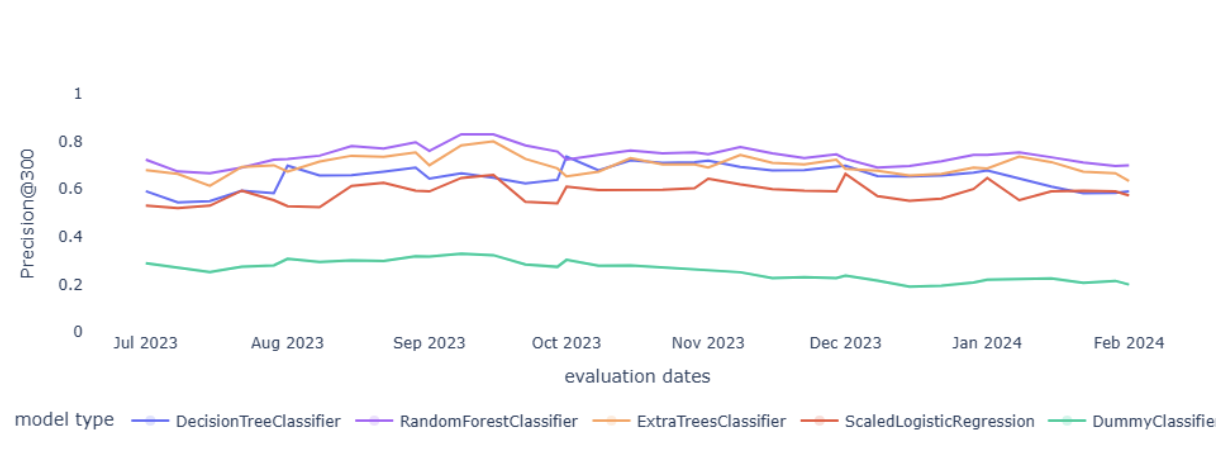
La gráfica 1 muestra que los métodos de ensamble superan de forma consistente a las líneas base y a los modelos más simples. En particular, Random Forest alcanza una Precision@300 cercana a 0.73 durante 2023–2024, mientras que Extra Trees se mantiene muy próximo a ese desempeño. En términos operativos, una precisión de 0.73 implica que, en promedio, alrededor de 219 de las 300 carpetas sugeridas por semana efectivamente salen de MAT en el periodo de seis meses. Esta lectura centrada en el volumen de revisión es más informativa para la gestión que métricas globales desancladas del uso cotidiano, ya que vincula directamente el rendimiento del modelo con la capacidad semanal de seguimiento. Además del promedio anual, la serie temporal revela una estabilidad apreciable: las brechas frente a la selección aleatoria y el ranking de tasa base se sostienen semana a semana, lo que refuerza la viabilidad de utilizar la lista prioritaria como insumo recurrente en la operación.
¿Qué características explican el comportamiento del mejor modelo?
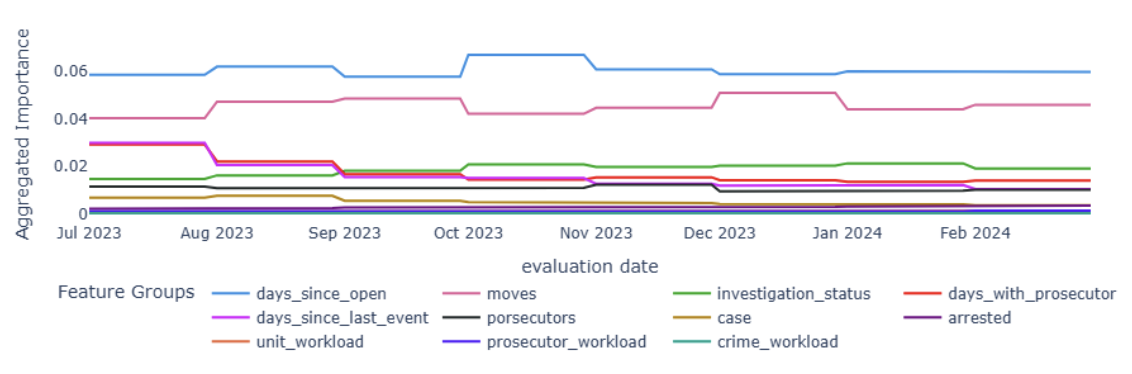
El análisis de importancia de variables en los mejores Random Forest apunta a que la dinámica procedimental es la principal fuente de información predictiva. Los movimientos—como cambios de estado y transferencias—aparecen sistemáticamente entre las características más influyentes, al igual que la antigüedad de la carpeta y los días transcurridos desde el último evento, dos medidas que capturan de manera complementaria la madurez y el ritmo reciente del expediente. También aportan información los estados que reflejan transiciones en la investigación, especialmente cuando se observan acumulados y promedios en ventanas recientes. Un hallazgo consistente es el peso de los eventos etiquetados como inicialización en periodos de 12, 6 y 24 meses: esta etiqueta no significa reabrir un caso cerrado, sino la re-iniciación formal que ocurre cuando una carpeta se transfiere entre unidades y genera una nueva entrada. La recurrencia de estas re-iniciaciones parece funcionar como marcador de “carpetas en movimiento”, es decir, expedientes que, por su patrón de actividad, tienen mayor probabilidad de transitar fuera de MAT en el corto plazo. En contraste, los rasgos estrictamente estáticos—como el tipo penal considerado de forma aislada—explican menos que la trayectoria temporal, lo que subraya la relevancia de modelar no sólo qué es un caso, sino cómo se está comportando en el tiempo. La gráfica 2 muestra estos resultados.
¿Qué sigue?
Más allá de los buenos resultados en datos históricos, queremos saber si el sistema funciona en producción y mejora el trabajo de la fiscalía. Para eso haremos un ensayo controlado aleatorizado (RCT) semanal: el modelo calcula un score para todas las carpetas abiertas, toma las 600 con mayor score de finalizar y las divide al azar en 300 de tratamiento (lista visible para revisión prioritaria) y 300 de control (flujo habitual). El personal operativo no conoce la asignación y damos seguimiento por seis meses para comparar tasa y tiempo de salida entre grupos. Si el RCT muestra mejoras significativas a favor del tratamiento, integraremos la herramienta al ciclo semanal de priorización.
Limitaciones y alcances
El modelo se desempeña bastante bien en datos históricos, pero su alcance se restringe a MAT: el desenlace previsto es la salida de MAT, no la resolución jurisdiccional final. Esta delimitación es intencional, pues el objetivo inmediato es mejorar la gestión de capacidad en la unidad de entrada. Los resultados dependen de la información en el PIE, que no incorpora narrativas ni evidencia digitalizada; los modelos podrían mejorar si se entrenaran también con dicha información. El marco metodológico es replicable en otras dependencias, aunque su adopción requeriría ajustes en la ingeniería de características y en la integración operativa para reflejar catálogos y flujos locales. En caso de que el RCT corrobore mejoras significativas en tasa y tiempo de salida, el siguiente paso razonable sería explorar su despliegue en otras unidades (por ejemplo, especializadas) con la correspondiente adaptación de variables y umbrales a sus condiciones específicas.
Conclusión
La evidencia histórica indica que es posible priorizar semanalmente las carpetas con mayor probabilidad de salir de MAT en el corto plazo a partir de registros procedimentales y modelos interpretables. Los métodos de ensamble—en particular Random Forest—alcanzan una Precision@300 cercana a 0.73, con estabilidad entre semanas y ventajas claras frente a referencias simples. Un ensayo controlado aleatorizado (RCT) permitirá estimar el impacto causal sobre las tasas y los tiempos de salida y, con ello, sustentar la decisión de integrar la lista prioritaria como componente regular del trabajo operativo. El aporte de esta aproximación no es sustituir el criterio profesional, sino hacer visibles, a tiempo y de manera consistente, aquellas carpetas cuyo patrón de actividad sugiere una resolución próxima dentro del flujo institucional, a fin de contribuir a mejorar el trabajo que realiza la Fiscalía; priorizar con evidencia libera tiempo para lo sustantivo y acerca soluciones más rápidas a las personas que las necesitan.
INEGI. (2023). Estadísticas de procuración de justicia en México. Instituto Nacional de Estadística y Geografía.
México Evalúa. (2023). Hallazgos del sistema de justicia penal en México 2023. México Evalúa.
Sobrino, F., De Unanue, A., Hernández, E., Villalobos, E.,Cisneros, S., Aké, D., Camacho Osnay, C. P., García Neri, A., & Hernández, I. (2025). Improving criminal case management through machine learning system (manuscrito inédito). Centro de Ciencia de Datos – EGobiernoyTP, Tecnológico de Monterrey; Fiscalía General de Justicia del Estado de Zacatecas.