Record Linkage: ¿Qué hacer cuando tienes registros diferentes que refieren a la misma persona?
27 de Febrero de 2026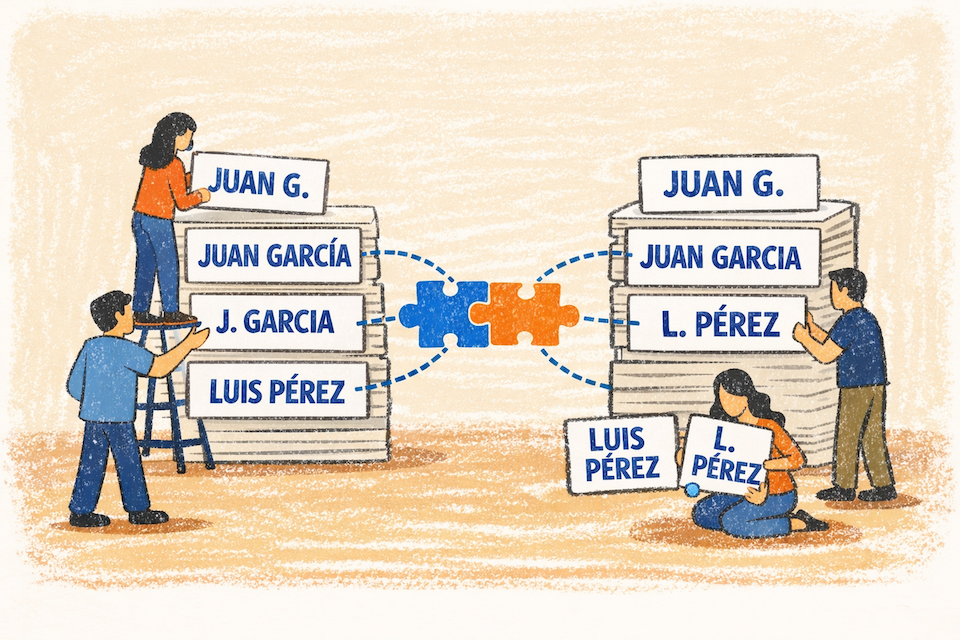

Elena Villalobos Nolasco
Profesora-investigadora
¿Te ha pasado que tienes una base de datos donde una sola persona aparece registrada con diferentes identificadores únicos? ¿O que manejas varias bases que posiblemente tienen a las mismas personas, pero no estás seguro de cómo comprobarlo? ¿O tal vez los nombres están escritos con errores tipográficos y no sabes si realmente se trata del mismo registro? Y no solo ocurre con personas: también puede pasar con nombres de organizaciones, empresas, direcciones, consignatarios o clientes que aparecen duplicados o escritos de formas ligeramente diferentes en bases separadas o en la misma base.
Estos escenarios son comunes cuando integramos información de distintas fuentes. El mismo individuo puede aparecer con un apellido abreviado, un nombre incompleto, una fecha en formato distinto o un identificador con dígitos faltantes. En este blog te voy a hablar de Record Linkage, un proceso que nos ayuda a identificar y vincular registros que representan la misma entidad, aunque los datos no coincidan de manera exacta.
¿Qué es Record Linkage?
El Record Linkage —o vinculación de registros— es un conjunto de técnicas diseñadas para integrar información dispersa que proviene de diferentes fuentes. Su objetivo es identificar cuándo dos o más registros hacen referencia a la misma entidad, ya sea una persona, una empresa o cualquier otra unidad de análisis, incluso cuando existen pequeñas diferencias entre los campos.
En muchas organizaciones, los datos sobre un mismo individuo pueden encontrarse repartidos en distintas fuentes: con nombres escritos de manera diferente, con identificadores incompletos o con información registrada de manera inconsistente. Record Linkage permite unir esas piezas y construir una visión más completa y coherente. Además, ayuda a detectar duplicados —deduplicación—, es decir, registros que refieren a la misma entidad, aunque aparezcan bajo variaciones distintas.
Para aplicar Record Linkage de manera efectiva, es indispensable entender el contexto de los datos: cómo se recolectaron, qué transformaciones han sufrido y qué tan confiables son las variables que se utilizarán para vincular los registros. Este conocimiento contextual permite diseñar reglas de comparación adecuadas y evaluar de mejor manera los resultados.
Consideraciones éticas, de protección de datos y de seguridad antes de continuar
Record Linkage involucra trabajar con información sensible y, por tanto, requiere una gran responsabilidad ética y legal. Además de contar con acuerdos de confidencialidad y controles de seguridad robustos, es esencial garantizar privacidad, trazabilidad y transparencia, tanto en los procesos técnicos como en las decisiones derivadas de ellos.
En muchos proyectos, los conjuntos de datos no incluyen nombres o direcciones para proteger la identidad de las personas. Sin embargo, esos campos suelen ser los más útiles para vincular registros entre bases. El desafío está en equilibrar la necesidad de identificar coincidencias con la obligación de preservar la privacidad. Existen estrategias para lograrlo, como recurrir a instituciones neutrales que realizan el linkage y devuelven únicamente resultados anonimizados, o emplear métodos criptográficos que permiten comparar identificadores sin exponerlos directamente (Tokle & Bender, 2021).
En el Centro de Ciencia de Datos e IA, recientemente implementamos un proceso bajo ese principio: la comparación entre registros se llevó a cabo dentro de la organización propietaria de los datos, mientras que el Centro solo tuvo acceso a resultados intermedios —valores de similitud que no revelan información original—. Con esa base ética y de seguridad bien establecida, podemos pasar al lado práctico del proceso. ¿Cómo se lleva a cabo un Record Linkage de manera controlada y reproducible?
Enfoques para Record Linkage
No existe un único método para vincular registros. En la práctica, los enfoques se agrupan en tres grandes familias.
El enfoque determinístico se basa en reglas y scores ponderados. Se definen manualmente las métricas de similitud, los pesos de cada atributo y los umbrales de decisión. Es transparente, interpretable y no requiere datos etiquetados. Su principal limitación es que depende del criterio del analista para calibrar parámetros.
El enfoque probabilístico parte del modelo de Fellegi y Sunter (1969), que calcula la probabilidad de que un par de registros sea una coincidencia real. Para cada comparación se calculan dos probabilidades: la de observar ese valor de similitud si los registros realmente coinciden (m-probabilidad) y la de observarlo si no coinciden (u-probabilidad). Estos pesos suelen estimarse mediante Expectation-Maximization (EM) y producen un score probabilístico con fundamento estadístico explícito. Herramientas como Splink (MOJ Analytical Services) implementan este enfoque de forma escalable.
El enfoque basado en machine learning aprende a clasificar pares como “match” o “no match” a partir de ejemplos etiquetados. Puede lograr alto desempeño, pero requiere un conjunto de entrenamiento cuidadosamente construido y mayor infraestructura computacional.
La elección del método depende de la disponibilidad de etiquetas, los recursos computacionales y el nivel de interpretabilidad requerido. En el Centro hemos implementado diversos pipelines de Record Linkage, principalmente bajo un enfoque determinístico basado en scores ponderados, cuyo esquema general se describe a continuación.
Pipeline de Record Linkage
El flujo —o pipeline— que seguimos combina etapas estadísticas y lógicas que permiten identificar cuándo distintos registros se refieren a la misma entidad. En la Figura 1 se muestra el panorama general: el trabajo inicia con dos fuentes de información y pasa por bloqueo, cálculo de similitud, construcción de score, filtros, emparejamiento con grafos y validación.
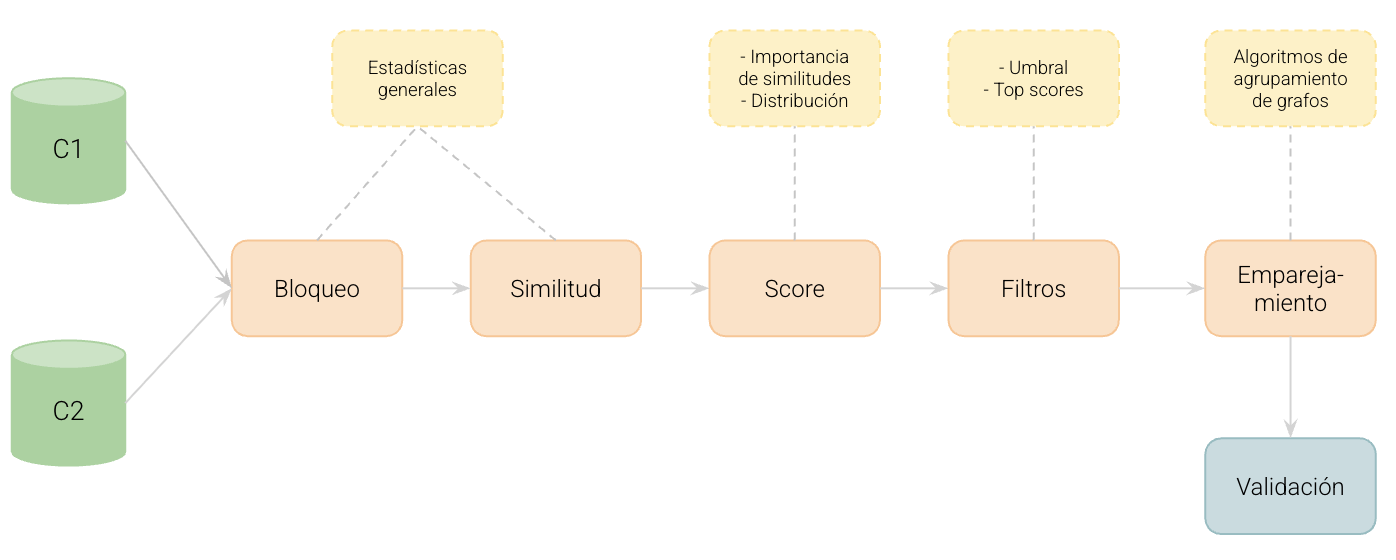
Bloqueo
Uno de los principales retos en Record Linkage es el costo computacional de comparar cada registro contra todos los demás. Si una base tiene n registros, el número de comparaciones posibles crece cuadráticamente (n²). En proyectos con miles o millones de observaciones, esto resulta costoso de procesar.
Para hacer el proceso eficiente, aplicamos una técnica llamada bloqueo, que consiste en restringir las comparaciones únicamente a pares de registros que probablemente estén vinculados (Tokle & Bender, 2021). El bloqueo actúa como un filtro previo: reduce el espacio de búsqueda y permite concentrar el cómputo en candidatos plausibles.
Existen distintas estrategias de bloqueo y su diseño depende del contexto. En nuestras implementaciones, por ejemplo, hemos utilizado reglas simples como agrupar por las primeras letras del nombre (ver Tabla 1) o por combinaciones de iniciales. Estas reglas reducen drásticamente el número de comparaciones y suelen capturar una proporción importante de coincidencias.
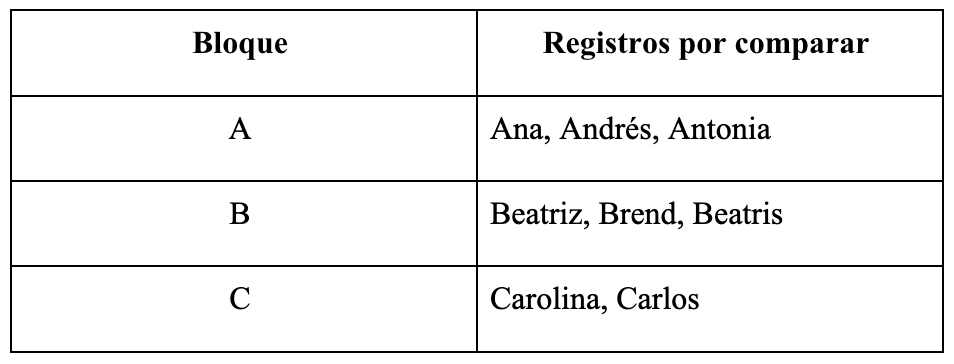
Este paso es crucial porque un bloqueo demasiado estricto puede omitir coincidencias reales, mientras que un bloqueo demasiado laxo incrementa innecesariamente el costo computacional. Cuando el volumen es muy grande o el ruido es alto, pueden emplearse estrategias más avanzadas (por ejemplo, variantes por vecindad ordenada o hashing aproximado), pero el principio central se mantiene: reducir comparaciones sin perder matches relevantes.
También suele ser útil aplicar múltiples bloqueos. Por ejemplo, uno por inicial del apellido y otro por inicial del nombre, y luego unir los candidatos obtenidos. Esta estrategia, conocida como multi-pass blocking, permite recuperar coincidencias que se perderían con una sola regla, especialmente ante errores de captura o variaciones en el uso de apellidos. La desventaja es que aumenta el número de comparaciones, por lo que conviene monitorear el tamaño de los bloques y ajustar reglas adicionales para mantener el costo bajo control.
Similitud
Una vez que hemos reducido el número de comparaciones mediante el bloqueo, el siguiente paso es medir qué tan parecidos son los registros dentro de cada bloque. Esta etapa también suele conocerse como fuzzy matching: se usan métricas de coincidencia aproximada en lugar de exigir igualdad exacta entre cadenas de texto.
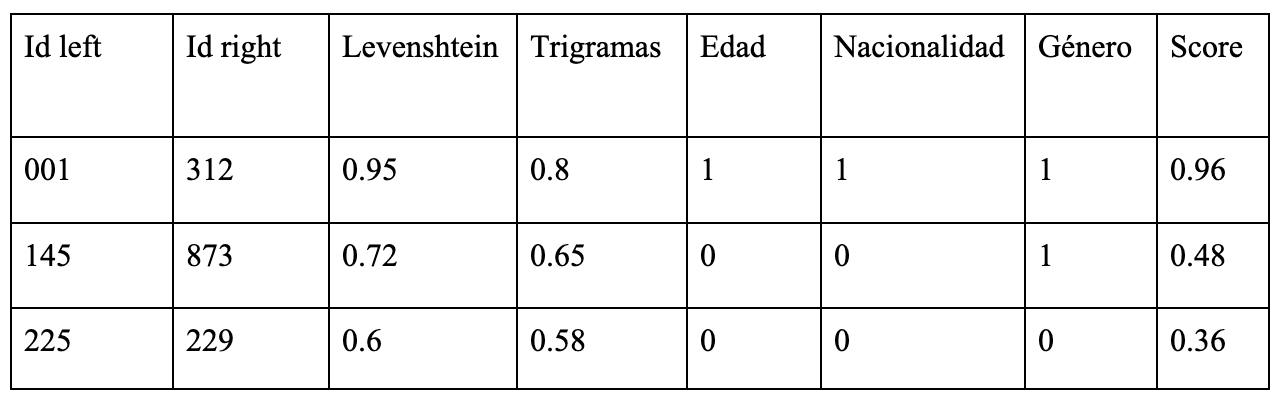
Antes de comparar, es necesario realizar un preprocesamiento: eliminar caracteres especiales, convertir a minúsculas, normalizar acentos y limpiar ruido. Después, para decidir si dos registros representan a la misma entidad, no solo se comparan los nombres: también pueden usarse CURP, RFC, edad, género, nacionalidad o dirección, según la disponibilidad y calidad.
Entre las métricas de similitud de texto más comunes se encuentran la distancia de Levenshtein (ediciones necesarias para transformar una cadena en otra), los trigramas (comparación de secuencias de tres caracteres) y Jaro/Jaro–Winkler, útil para nombres por su tolerancia a transposiciones y peso a prefijos. Para variables numéricas como edad o fecha de nacimiento, se puede usar diferencia absoluta o tolerancias; para atributos categóricos, coincidencia exacta.
El resultado de esta etapa es una tabla de comparaciones, donde cada fila representa un par de registros y cada columna muestra la similitud en algún atributo.
Un punto que suele definir el desempeño del linkage es cómo tratamos valores faltantes y atributos inestables. Si un campo clave está vacío en uno de los registros, no necesariamente debemos penalizarlo igual que una discrepancia; muchas implementaciones separan explícitamente “missing” de “no match”. También conviene estandarizar representaciones antes de comparar: nombres compuestos, abreviaturas comunes, prefijos y formatos de fecha. Estas decisiones parecen menores, pero pueden mover muchos casos del rango “gris” hacia coincidencias claras o descartes más seguros.
En la siguiente etapa, estas métricas se combinan para generar un score final.
Score
Una vez calculadas las métricas individuales, el siguiente paso es combinarlas para obtener una medida global de similitud entre dos registros: el score. Éste, resume la evidencia de que dos registros se refieren a la misma entidad, considerando varios atributos al mismo tiempo.
Una forma práctica de construirlo es asignar pesos según la confiabilidad, importancia y capacidad discriminativa de cada atributo. Coincidencias fuertes en variables clave elevan el score; discrepancias en atributos relevantes lo reducen. El resultado es un valor continuo entre 0 y 1, flexible e interpretable, que permite ordenar y priorizar pares candidatos.
Filtro de scores
Una vez calculado el score, el siguiente paso es depurar y seleccionar vínculos confiables. Un primer filtro consiste en definir un umbral mínimo (por ejemplo, 0.8) y conservar solo los pares que lo superan. Si el umbral se fija demasiado alto, se pierden coincidencias reales; si se fija demasiado bajo, aumentan falsos positivos. Por eso conviene ajustar el umbral con base en la distribución de scores y el contexto del proyecto.
Incluso tras aplicar el umbral, un registro puede quedar vinculado con varios otros. Para priorizar las coincidencias más sólidas, se ordenan los vínculos de mayor a menor score y se conserva solo un número fijo de los mejores (por ejemplo, top-2). Así se evita que un registro se conecte con demasiados candidatos y se mantiene una estructura más clara e interpretable.
Tras aplicar los filtros, se obtiene un conjunto de coincidencias de alta confianza que puede modelarse como un grafo: cada nodo representa un registro y cada arista una relación confiable entre dos registros. Este grafo es la base para el siguiente paso.
Emparejamiento
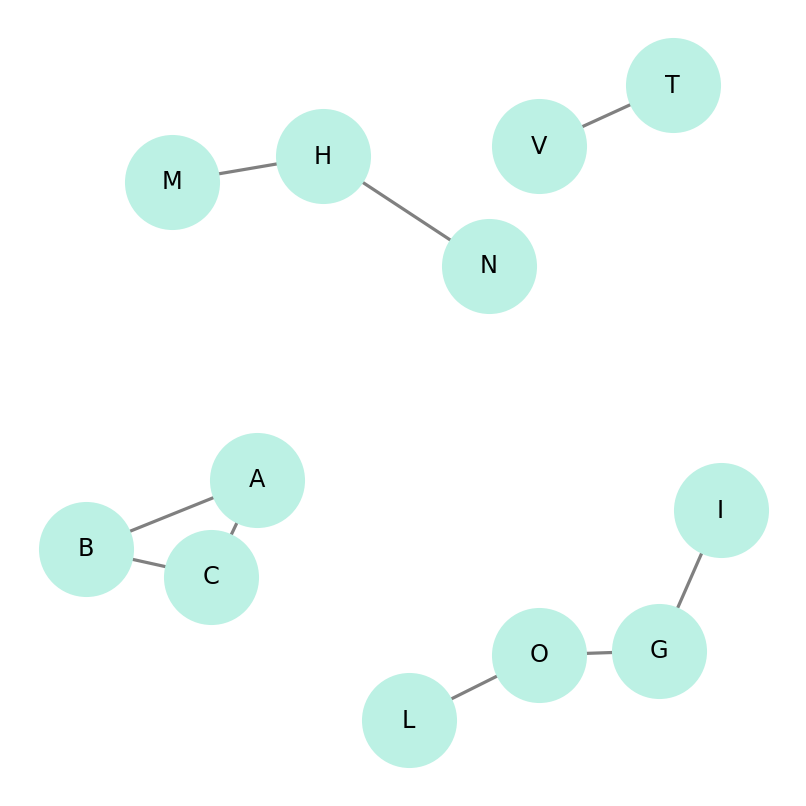
A partir de ese grafo filtrado, llega el momento de agrupar registros que probablemente pertenecen a la misma entidad. Esto se logra identificando los componentes conectados del grafo: conjuntos de nodos que están unidos directa o indirectamente por relaciones de alta similitud. Cada uno de estos componentes corresponde a una entidad reconstruida.
En términos simples, si el registro A se vincula con B y B se vincula con C, el algoritmo puede concluir que A, B y C forman parte del mismo grupo, aunque A y C no estén conectados directamente.
Para identificar estos grupos pueden usarse distintos métodos; en la práctica, DSU (Union-Find) es eficiente para grafos grandes, mientras que BFS y DFS son útiles en grafos moderados o cuando interesa analizar el recorrido. El resultado es un conjunto de grupos de registros equivalentes, donde cada grupo representa una entidad reconstruida a partir de varias fuentes (ver Figura 2.).
Un riesgo importante es el cierre transitivo: cadenas de registros conectadas por eslabones débiles pueden terminar en el mismo grupo. Para mitigarlo, pueden aplicarse restricciones adicionales, como exigir que los pares dentro de un grupo superen un umbral mínimo, limitar el tamaño máximo de los grupos y revisar manualmente componentes inusualmente grandes.
Validación de resultados
Una vez que se han formado los grupos vinculados, el paso final es validar que los enlaces sean correctos. Record Linkage nunca es perfecto: los datos suelen contener errores de captura, valores faltantes o formatos inconsistentes, por lo que siempre existe un grado de incertidumbre. Por esta razón, los resultados deben evaluarse desde distintos ángulos.
Una estrategia común es la validación manual o cualitativa, especialmente en etapas tempranas. Esto puede implicar revisar ejemplos, inspeccionar casos ambiguos (scores cercanos al umbral) y detectar patrones de error. Esta revisión no solo sirve para aceptar o rechazar coincidencias, sino que se convierte en un proceso iterativo que permite ajustar pesos, umbrales y estrategias de comparación. Precisamente por su carácter iterativo, es recomendable desarrollar un pipeline reproducible y auditable, además de documentar las decisiones tomadas (reglas de bloqueo, pesos y umbrales).
Otra estrategia con un énfasis más cuantitativo es seleccionar una muestra aleatoria de pares o grupos y revisarla manualmente. Además, cuando se cuenta con algunos datos etiquetados, se puede calcular precisión, recall y F1-score.
La exigencia de la validación depende del uso que se dará a los resultados. Si los vínculos se emplearán para análisis exploratorio o generación de variables para modelos de machine learning, puede tolerarse cierto margen de error. En cambio, cuando los enlaces influyen en procesos punitivos, asignación de beneficios o decisiones con consecuencias legales o administrativas, la validación debe ser mucho más rigurosa. En la práctica, la pregunta guía es: ¿qué pasa si este enlace está mal? La respuesta determina el nivel de rigor necesario.
Conclusiones
El Record Linkage es mucho más que un conjunto de técnicas para unir registros: es un proceso analítico, iterativo y contextual. Involucra decisiones técnicas —bloqueo, similitud, score, filtros y grafos—, pero también consideraciones éticas, legales y prácticas sobre el uso de los datos y las consecuencias de los resultados.
A lo largo de este blog vimos que no existe una receta única ni un proceso perfecto. Cada proyecto requiere adaptar el pipeline al contexto: elegir atributos relevantes, definir estrategias de similitud, calibrar pesos y umbrales, y validar con el rigor apropiado. Si trabajas con datos que podrían beneficiarse de esta técnica, probablemente ya diste el primer paso: reconocer que el problema existe y que puede abordarse de manera controlada y reproducible.
Tokle, J., & Bender, S. (2021). Record Linkage. In I. Foster, R. Ghani, R. Jarmin, F. Kreuter, & J. Lane (Eds.), Big Data and Social Science: Data Science Methods and Tools for Research and Practice (2nd ed., pp. 63–90). CRC Press.
Fellegi, Ivan P., and Alan B. Sunter. 1969. “A Theory for Record Linkage.” Journal of the American Statistical Association 64 (328). Taylor & Francis Group: 1183–1210.
Splink. (s. f.). Introduction – Topic Guides. MOJ Analytical Services. Recuperado de https://moj-analytical-services.github.io/splink/topic_guides/topic_guides_index.html
Hernández, M. A., & Stolfo, S. J. (1995). The Merge/Purge Problem for Large Databases. In Proceedings of the 1995 ACM SIGMOD International Conference on Management of Data (pp. 127–138). ACM.
McCallum, A., Nigam, K., & Ungar, L. H. (2000). Efficient Clustering of High-Dimensional Data Sets with Application to Reference Matching. In Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (pp. 169–178). ACM.
Christen, P. (2012). A Survey of Indexing Techniques for Scalable Record Linkage and Deduplication. IEEE Transactions on Knowledge and Data Engineering, 24(9), 1537–1555. doi:10.1109/TKDE.2011.127
Gionis, A., Indyk, P., & Motwani, R. (1999). Similarity Search in High Dimensions via Hashing. In Proceedings of the 25th International Conference on Very Large Data Bases (pp. 518–529).
Kaufman, A. R., & Klevs, A. (2022). Adaptive Fuzzy String Matching: How to Merge Datasets with Only One (Messy) Identifying Field. Political Analysis, 30(4), 590–596. doi:10.1017/pan.2021.38